
计算机教育缺失的一环_2
前言
这是本人观看该课程所做的第二部分的笔记,因为怕篇幅过长,所以这次只包含第4、5课的内容,水平有限,不一定全面。课后习题这边只贴出了部分个人觉得容易有问题的题目以及个人的答案,一些不好写题解的也没有放上来。
课程链接:点击这里
中文讲义:点击这里
第4讲 - 数据整理
数据整理的定义
任何把一种格式的数据转换成另一种格式的数据的过程都可以被称为“数据整理”。比如在前几节课中,我们使用管道操作符把一个程序的输出传递给另一个程序,这就是做数据整理的一种方式。
数据整理的示例
学习数据整理有两样东西是必不可少的:用来整理的数据以及相关的应用场景。
这节课将采用一个服务器上的系统日志作为数据源。
(PS:日志处理通常是一个比较典型的使用场景,因为我们经常需要在日志中查找某些信息,这种情况下通读日志是不现实的,因此就需要数据整理。)
目的:获取日志中所有的用户断开连接时打印的日志中的用户名称。
查看所有登录服务器的用户且涉及
ssh的信息,命令如下:1
ssh 服务器名 journalctl | grep ssh
ssh是一种通过命令行远程访问计算机的方式,journalctl用于查看系统日志。
部分结果如图: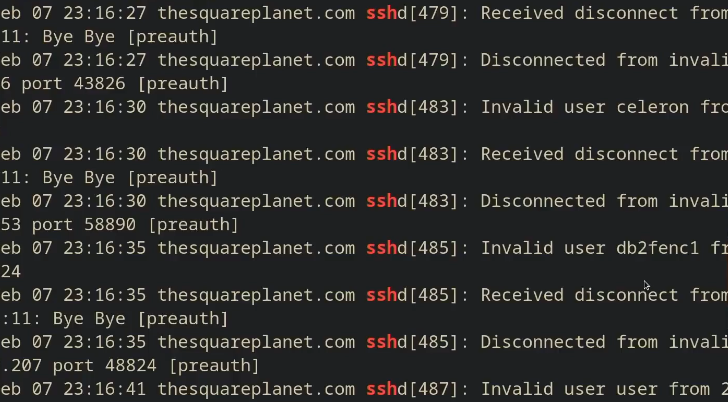
在这个基础上,我们想查看所有用户断开连接时输出的日志,命令如下:
1
ssh 服务器名 journalctl | grep ssh | grep "Disconnected from"
但是有个问题,这行命令会将所有的日志文件传到本地的电脑上再进行筛选过滤,但我们并不关心除了目标之外的日志内容,这样的操作显得过于笨重且浪费资源。所以我们优化命令如下:
1
ssh 服务器名 'journalctl | grep ssh | grep "Disconnected from"' | less
这行命令会在服务器上执行相同筛选操作,然后将最终结果通过管道符输入到
less进行分页查看。
除此之外,我们也可以直接将结果保存到本地的文件中,这样就不用每次都通过网络去费事费力的请求这些内容,命令如下:1
2ssh 服务器名 'journalctl | grep ssh | grep "Disconnected from"' > ssh.log # 保存到ssh.log文件中
vim ssh.log即使进行过滤之后,文件的内容依旧包含了许多无用的信息。要想进一步过滤,我们在这里引入
sed这个流编辑器。在sed中,我们基本上是利用一些简短的命令来修改文件,而不是直接操作文件的内容,最常用的命令是s,即替换命令,具体示例如下:1
cat ssh.log | sed 's/.*Disconnected from//'
s命令的语法如下:s/REGEX/SUBSTITUTION/, 其中REGEX部分是我们需要使用的正则表达式,而SUBSTITUTION是用于替换匹配结果的文本。
所以这里是将所有日志记录的 ‘Disconnected from’ 以及它前面的日期,主机名和进程替换为空。因为我们对日志里记录的日期,主机名和进程并不感兴趣,而 ‘Disconnected from’ 对于我们来说也是每行都有的无用信息了。
部分结果如图: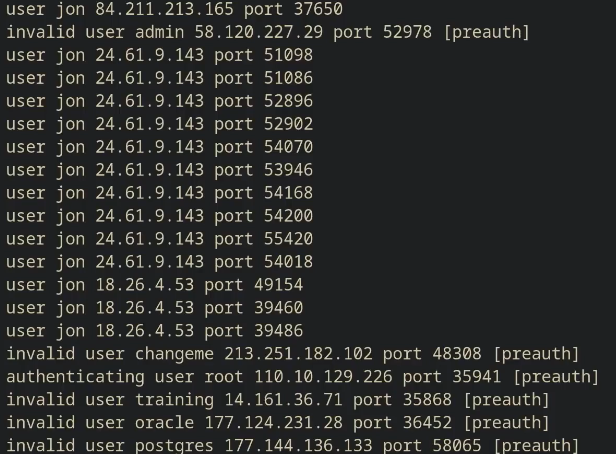
( PS: 常用正则表达式介绍:
.除换行符之外的”任意单个字符”*匹配前面字符零次或多次+匹配前面字符一次或多次[abc]匹配 a, b 和 c 中的任意一个(RX1|RX2)任何能够匹配 RX1 或 RX2 的结果^匹配行首$匹配行尾
注意,.*通常是贪婪匹配,.*?将其变为非贪婪匹配。
)
sed中的操作一般是非贪婪的,如果需要更改可以使用’g’修饰符,比如:
1 | : echo 'bbac' | sed 's/[ab]//' |
sed仅支持一些非常老的正则表达式,通常在运行的时候建议使用-E使它能够用更现代的语法来支持更多内容,不然就要使用转义符\。
例如:
1 | : echo 'abcaba' | sed 's/(ab)*//g' |
回到日志数据处理,接下来我们要想办法提取用户名了。
先写出能够匹配所有行的正则表达式,如下所示:
1 | cat ssh.log | sed -E 's/.*?Disconnected from (invalid |authenticating )?user .* [^ ]+ port [0-9]+( \[preauth\])?$//' |
[^ ]+会匹配任意非空且不包含空格的序列。
写出匹配全文的正则后,我们希望获取到用户名,对此,我们可以使用捕获组来完成。在圆括号内的正则表达式匹配到的文本,都会被存入一系列以编号区分的捕获组中。捕获组的内容可以在替换字符串时使用,例如\1,\2,\3等等,因此可以使用如下命令:
1 | cat ssh.log | sed -E 's/.*?Disconnected from (invalid |authenticating )?user (.*) [^ ]+ port [0-9]+( \[preauth\])?$/\2/' |
这个命令的意思就是匹配整行,然后将其替换为第二个捕获组匹配的值。
写正则表达式需要有足够的耐心,面对数据量很大的情况下很难一下就能写出能够写出合适的正则表达式(比如匹配邮箱,至今依旧有很多人在网上讨论这个问题)。我们可以使用’| head -n行数’去逐步扩大匹配数据的范围,也可以借助正则调试器。而且也要注意是不是该用正则解决问题,比如解析JSON就别用正则,该用别的工具就用别的。
- 现在我们有了用户名称的列表,但依旧不是很理想。
一些优化操作:
统计行数:
1
cat ssh.log | sed -E 's/.*?Disconnected from (invalid |authenticating )?user (.*) [^ ]+ port [0-9]+( \[preauth\])?$/\2/ | wc -l'
转换为有序列表,去重并打印出重复的行数(作为前缀)
1
cat ssh.log | sed -E 's/.*?Disconnected from (invalid |authenticating )?user (.*) [^ ]+ port [0-9]+( \[preauth\])?$/\2/ | sort | uniq -c'
如图所示:
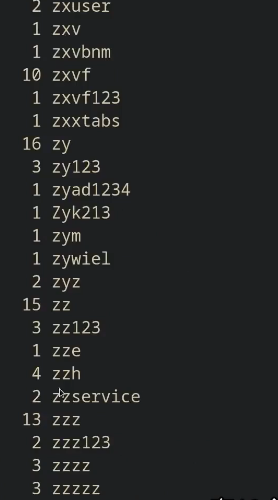
我们还有:
1
cat ssh.log | sed -E 's/.*?Disconnected from (invalid |authenticating )?user (.*) [^ ]+ port [0-9]+( \[preauth\])?$/\2/ | sort | uniq -c | sort -nk1,1'
sort -nk1,1表示根据输入的第一列进行数字排序。-n会按照数字顺序对输入进行排序(默认情况下是按照字典序排序),-k表示输入的列是以空格为分隔符,-k1,1表示以第一列为开头,第一列为结尾。sort默认是升序的,所以用tail可查看前几名的结果,head可查看后几名的结果。如果想要降序,使用sort -r。获取用户名,而且不要一行一个地显示。
1
cat ssh.log | sed -E 's/.*?Disconnected from (invalid |authenticating )?user (.*) [^ ]+ port [0-9]+( \[preauth\])?$/\2/ | sort | uniq -c | sort -nk1,1 | awk '{print $2}' | paste -sd,'
awk是一个基于列的流处理器,默认将输入解析为以空格为分隔符的列,然后再单独操作这些列,awk '{print $2}'表示仅打印第二列。paste命令用来合并行(-s),并指定一个分隔符进行分割(-d),这里指定,为分隔符。
awk,另一种编辑器。
还是上面的例子,让我们统计一下所有以 c 开头,以 e 结尾,并且仅尝试过一次登录的用户,命令如下:1
cat ssh.log | sed -E 's/.*?Disconnected from (invalid |authenticating )?user (.*) [^ ]+ port [0-9]+( \[preauth\])?$/\2/ | sort | uniq -c | awk '$1 == 1 && $2 ~ /^c.*e$/ {print $0}'
$0表示整行的内容,$1到$n为一行中的 n 个区域,区域的分割基于 awk 的域分隔符(默认是空格,可以通过-F来修改)。awk是一种编程语言。即使你可能永远都用不到,你也应该知道可以这样用:1
2
3
4cat ssh.log | sed -E 's/.*?Disconnected from (invalid |authenticating )?user (.*) [^ ]+ port [0-9]+( \[preauth\])?$/\2/ | sort | uniq -c | awk
'BEGIN { rows = 0 }
$1 == 1 && $2 ~ /^c[^ ]*e$/ { rows += $1 }
END { print rows }'在第 0 行定义变量 rows 为 0 ,然后每成功匹配一次, rows + 1 ,一直到最后一行,打印 rows 的值。效果等同于
wc -l。其他一些工具
bc: 伯克利计算器。
示例:1
2:echo "1 + 2" | bc -l # -l参数基本必加
3更复杂一点的,比如统计非单次登录的总数:
1
at ssh.log | sed -E 's/.*?Disconnected from (invalid |authenticating )?user (.*) [^ ]+ port [0-9]+( \[preauth\])?$/\2/ | sort | uniq -c | awk '$1 != 1 { print $1 }' | paste -sd+ | bc -l
R语言也可以实现相同的操作。
gnuplot:从标准输入中获取内容的绘图工具。
(不详细展开了,感兴趣的建议自行去了解)。两种特殊的数据整理方法
命令行参数整理
将输入转变为命令行参数,使用xargs,示例:1
rustup toolchain list | grep nightly | grep -vE "nightly-x86" | sed 's/-x86.*//' | xargs rustup toolchain uninstall
最终
xargs会把输入变为rustup toolchain uninstall后的参数。如图所示:
整理二进制数据
ffmpeg用于编码和解码视频,某种程度上也可以处理图像。
例如我们可以用ffmpeg从相机中捕获一张图片,将其转换成灰度图后通过SSH将压缩后的文件发送到远端服务器,并在那里解压、存档并显示,示例如下:1
2
3
4fmpeg -loglevel panic -i /dev/video0 -frames 1 -f image2 -
| convert - -colorspace gray -
| gzip
| ssh mymachine 'gzip -d | tee copy.jpg | env DISPLAY=:0 feh -'
通过这几个简单的例子,我们可以看到管道的强大之处,这些管道传递的不必是文本数据,只是将任何格式的数据转换为另一种格式。
课后练习(部分)
- 统计 words 文件 (/usr/share/dict/words) 中包含至少三个a 且不以’s 结尾的单词个数。这些单词中,出现频率前三的末尾两个字母是什么? sed的
y命令,或者tr程序也许可以帮你解决大小写的问题。共存在多少种词尾两字母组合?还有一个很 有挑战性的问题:哪个组合从未出现过?
先来看第一个问题,统计words文件中包含至少三个a 且不以’s 结尾的单词个数,命令如下:
1 | cat /usr/share/dict/words | sed -E 'y/ABCDEFGHIJKLMNOPQRSTUVWXYZ/abcdefghijklmnopqrstuvwxyz/' | grep -E "^([^a]*a){3}.*$" | grep -v "'s$" | wc -l |
这边使用sed的y命令进行大小写转换,然后grep进行正则匹配。
第二个问题,这些单词中,出现频率前三的末尾两个字母是什么?
命令如下:
1 | cat /usr/share/dict/words | sed -E 'y/ABCDEFGHIJKLMNOPQRSTUVWXYZ/abcdefghijklmnopqrstuvwxyz/' | grep -E "^([^a]*a){3}.*$" | grep -v "'s$" | sed -E 's/^.*([a-z]{2})$/\1/' | sort | uniq -c | sort -nk1,1 |tail -n3 |
在前面的基础上,照着课上的思路走就行了。
第三个问题,共存在多少种词尾两字母组合?
命令如下:
1 | cat /usr/share/dict/words | sed -E 'y/ABCDEFGHIJKLMNOPQRSTUVWXYZ/abcdefghijklmnopqrstuvwxyz/' | grep -E "^([^a]*a){3}.*$" | grep -v "'s$" | sed -E 's/^.*([a-z]{2})$/\1/' | sort | uniq | wc -l |
没什么好说的,很直接。
最后一个问题,哪个组合从未出现过。
那我们就先生成一份包含所有组合的列表,然后与上述结果比较即可。
编写 words.sh :
1 | !/bin/bash |
赋予执行权限:
1 | chmod +x words.sh |
输出列表到 words.txt 文件:
1 | ./words.sh > words.txt |
输出我们的结果集到 com.txt 文件中:
1 | cat /usr/share/dict/words | sed -E 'y/ABCDEFGHIJKLMNOPQRSTUVWXYZ/abcdefghijklmnopqrstuvwxyz/' | grep -E "^([^a]*a){3}.*$" | grep -v "'s$" | sed -E 's/^.*([a-z]{2})$/\1/' | sort | uniq > com.txt |
输出所有没出现的结果
1 | diff --unchanged-group-format='' <(cat com.txt) <(cat words.txt) |
--unchanged-group-format=''用于将两个文件中相同的内容设置为空字符串,剩下的内容就是没出现的部分。
第5讲 - 命令行环境
任务控制
结束进程
当我们想要终止一个长时间执行的命令的时候,我们一般会使用Ctrl+C来停止命令的执行。在这里,我们的 shell 使用了一种名为信号的 Unix 通信机制,键入Ctrl+C 时,shell 会发送一个SIGINT信号到该进程,该信号表示信号中断,告诉程序停止自己。使用man signal 可查看具体的信息。
当一个进程接收到信号时,它会停止执行、处理该信号并基于信号传递的信息来改变其执行。就这一点而言,信号是一种软件中断。
虽然SIGINT和SIGQUIT(输入Ctrl+\可以发送该信号)都常常用来发出和终止程序相关的请求,但SIGTERM则是一个更加通用的、更加优雅的退出信号。为了发出这个信号我们需要使用kill命令,它的语法是:kill -TERM <PID>。
有时侯我们可以在程序中引入相应的包对信号进行捕获,比如捕获SIGINT。捕获信号的操作可以帮助我们去实现一些功能,比如程序的优雅退出。有些信号是不能捕获的,比如SIGKILL,它无论如何都会终止程序进程的执行,调用这种信号时必须非常注意。
暂停和后台执行进程
信号可以让进程做其他的事情,而不仅仅是终止它们。例如SIGSTOP(输入Ctrl+z可以发送该信号)会让进程暂停执行而不是终止。
命令中的&后缀可以让命令在直接在后台运行,这使得您可以直接在shell中继续做其他操作,不过它此时还是会使用shell的标准输出。
jobs命令会列出当前终端中尚未完成的全部任务。
我们可以使用bg %进程的标识号命令恢复暂停的工作,fg %进程的标识号 命令也是一样的,不过bg是在后台继续输出,fg恢复到前台并连接到标准输出。
kill命令常用于杀死进程,但kill命令也允许发送任何类型的Unix信号来执行其他的操作,而单单只是杀死进程,比如:kill -STOP %进程的标识号用于暂停指定的进程。
但我们关闭终端时,会发送SIGHUP信号终止所有的终端启动的进程。如果我们希望后台运行的进程在关闭终端时依旧能够运行,建议使用nohup命令启动后台进程,这样SIGHUP命令就会被忽略,如果想要终止可以发送kill信号,比如kill -KILL %进程的标识号。
具体操作结果如下: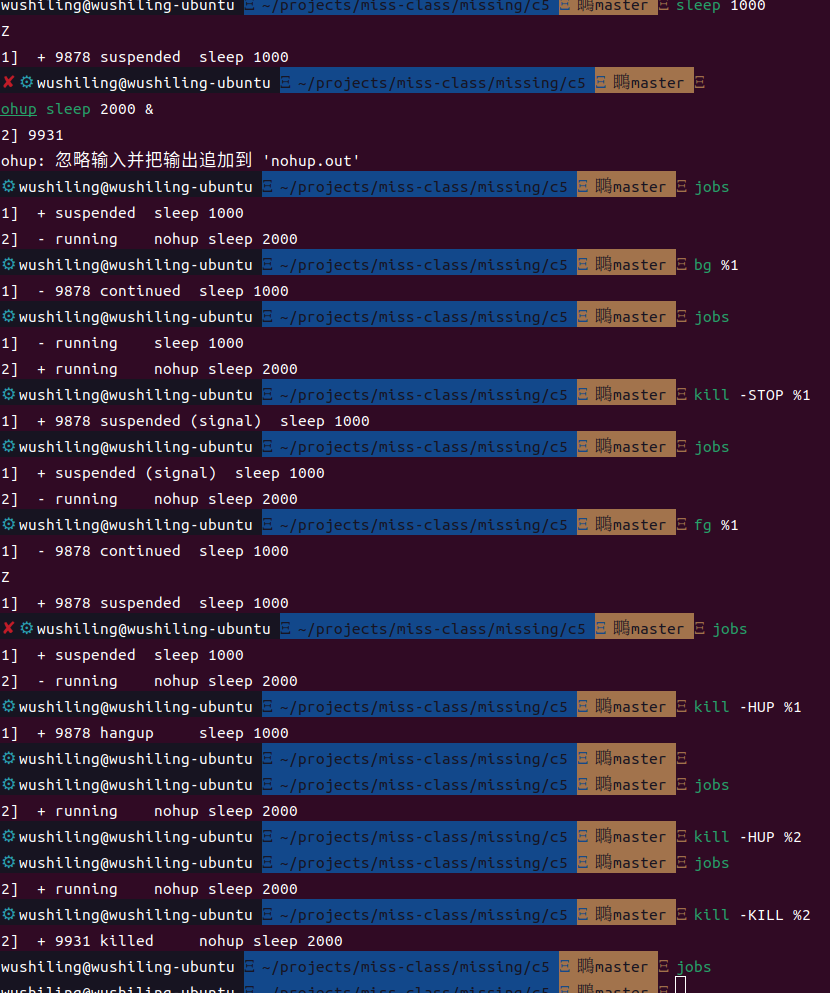
终端复用器
使用终端复用器可以帮助我们更加方便的使用命令行去处理多个不同的任务,这里介绍tmux这个终端复用器。(需要自行去安装)
tmux有三个核心概念:
- 会话
每个会话都是一个独立的工作区,其中包含一个或多个窗口。tmux开始一个新的会话。tmux new -t NAME以指定名称开始一个新的会话。tmux ls列出当前所有会话。Ctrl+b d,将当前会话分离。(注意,先按Ctrl+b,然后松开再按d)tmux a重新连接最后一个会话。您也可以通过-t来指定具体的会话。
- 窗口
可以理解为浏览器中的标签页。Ctrl+b c创建一个新的窗口,使用Ctrl+b d关闭Ctrl+b p切换到前一个窗口Ctrl+b n切换到下一个窗口Ctrl+b 窗口编号跳转到指定编号的窗口Ctrl+b ,重命名当前窗口Ctrl+b w列出当前所有窗口
- 面板
面板使我们可以在一个屏幕里显示多个shellCtrl+b "上下分割Ctrl+b %左右分割Ctrl+b <方向键>切换到指定方向的面板Ctrl+b <空格>将所有面板等距分布Ctrl+b z切换当前面板的缩放(将指定的面板放大到整个屏幕,再按一次返回)Ctrl+b [开始往回卷动屏幕。您可以按下空格键来开始选择,回车键复制选中的部分
dotfiles
别名
使用alias命令设置别名,比如:alias ll="ls -lah",这样执行ll就可以了而不用执行完整的命令。(注意, =两边是没有空格的,不然会被当成多个参数输入而设置失败)。
需要注意的是,别名并不是持久化的,关闭终端后所有别名就会消失。想要实现持久化,需要将相关的alias命令写入shell的启动那个文件中,像是.bashrc或.zshrc。
如图:

配置文件
很多程序的配置都是通过纯文本格式的配置文件来完成的也就是点文件。点文件的文件名以.开头,例如.vimrc,同时它们默认是隐藏文件,ls需要加上-a参数才能查看到。
具体的操作示例建议直接看视频,这边不好写。
想要进行更加具体的配置操作的话,可以去Github上找找其他人的配置文件,直接搜dotfiles就有很多。
符号链接的概念:
用一个dotfiles文件夹(在哪里无所谓)存储所有的点文件,当访问主目录的点文件(这个文件并没有实际的内容)时,会转到dotfiles文件夹内对应的点文件。这样做方便使用git统一管理,也方便查找。
如何高效地使用服务器
主要是操作安全shell(SSH)。
使用ssh登录远程服务器:
1 | ssh 用户名@服务器的IP地址 # 如果服务器有DNS名称的话可以使用URL替代IP地址 |
在前面数据整理这一课的时候,我们提到了通过ssh执行命令然后将数据返回给我们的本地主机:
1 | ssh foobar@server ls -la |
每次使用ssh都要输入密码有点过于繁琐了,我们可以使用ssh密钥来解决这个问题。ssh密钥使用非对称加密来创建一对密钥,公钥给服务器,私钥保存在本地,而后需要进行身份验证的时候,就不需要使用密码而是私钥进行身份验证了。
生成操作如图:
ssh会查询.ssh/authorized_keys来确认那些用户可以被允许登录。通过命令将公钥内容上传至服务器:
1 | cat .ssh/id_ed25519.pub | ssh jjgo@192.168.246.142 tee ~/.ssh/authorized_keys |
cat公钥的内容,传到ssh中,然后远程调用tee命令将输入写入到指定文件中。
通过ssh复制文件:
ssh+tee,上面那个就是scp 本地文件路径 用户名@IP地址:服务器上的目标文件路径rsync -avP 本地文件路径 用户名@IP地址:服务器上的目标文件路径。rsync是对scp的改进,可以检测本地和远端的文件以防止重复拷贝(之前上传终止的话下一次会从终止的地方开始拷贝而不是从头开始拷贝)。
可以使用~/.ssh/config进行配置。
示例:
1 | Host vm |
课后练习(部分)
- 如果您希望某个进程结束后再开始另外一个进程, 应该如何实现呢?在这个练习中,我们使用
sleep 60 &作为先执行的程序。一种方法是使用wait命令。尝试启动这个休眠命令,然后待其结束后再执行ls命令。但是,如果我们在不同的bash会话中进行操作,则上述方法就不起作用了。因为wait只能对子进程起作用。之前我们没有提过的一个特性是,kill命令成功退出时其状态码为0,其他状态则是非0。kill -0则不会发送信号,但是会在进程不存在时返回一个不为0的状态码。请编写一个bash函数pidwait,它接受一个pid作为输入参数,然后一直等待直到该进程结束。您需要使用sleep来避免浪费 CPU 性能。
示例脚本如下:
1 | #!/bin/bash |
- 剩下的题目就不贴了,因为实在不好写题解(懒)。


