
计算机教育缺失的一环_3
前言
这是本人观看该课程所做的第三部分的笔记,包含第6、7、8课的内容,水平有限,不一定全面。
课程链接:点击这里
中文讲义:点击这里
第6讲 - 版本控制(Git)
定义:版本控制系统是用于跟踪源代码或其他文件/文件夹的更改记录的工具。除了这些,还可以用于多人协作。版本控制系统通过一系列快照跟踪记录文件的更改,我们可以抓拍到文件夹的所有内容,然后可以为一系列的更改创造多个版本的快照,每个快照里都包含了最高层目录的所有内容。版本控制系统也维护了作者和提交时间戳等元数据。
为什么说版本控制很有用?
你可以用它查看旧版本的代码;查看提交信息来找出某些内容为什么被更改了,什么时候被更改的,被谁更改的,是属于谁负责的;使用不同分支并行处理;保持各个功能独立的情况下修复bug;解决多人同时更改统一部分代码引发的冲突等等。
虽然版本控制系统有很多,但事实上的标准却是Git。尽管Git的接口有些丑陋,但是它的底层设计和思想却是非常优雅的。这节课将通过一种自底向上的方式介绍Git,即先从底层数据模型开始,然后再介绍一些git命令。
Git 的数据模型
快照
Git将历史记录建模为某个顶层目录中的文件和文件夹的集合,一个简单的示例:
1 | <root> |
git在这里对这些东西建模采用的术语是这样子的: root 与 foo 被称为tree(文件夹),而我们通常称之为文件的东西,在这里称为blob。
历史记录建模:关联快照
线性历史记录是一种最简单的模型,它包含了一组按照时间顺序线性排列的快照。不过Git并没有采用这样的模型,而是使用了有向无环图来模拟历史。
在Git中每个快照都有一些父节点而不是一个,如下图: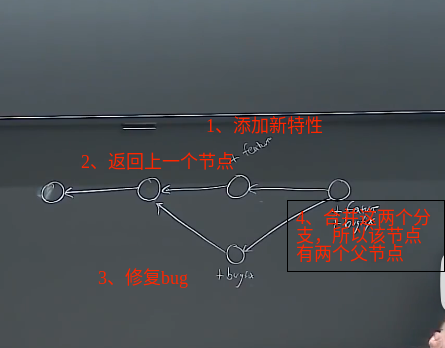
所以当节点合并的时候,就会出现多个父节点。
每个节点对应的是一个快照以及一些元数据(包含提交的作者,与此提交相关的描述信息等等)。
数据模型的伪代码表示
伪代码如下:
1 | // 文件就是一组数据 |
对象和磁盘数据存储以及伪代码表示
Git中的对象:
1 | type object = blob | tree | commit |
在Git中,所有 object 都是内容寻址的,所以Git存在磁盘上的是一组对象,保存在一个哈希表(objects)中。
1 | objects = map<string, object> // <对象内容的哈希值,对象的指针> |
引用(references)
所有的对象的 id 是40个字符长的十六进制字符串,SHA-1 是一个160位的哈希函数。这些 id 依旧是非常长的字符串,非常的不便。所以个Git的解决方式是使用引用,给这些哈希值赋予人类可读的名字。
引用是指向 commit 的指针。它是可变的,例如, master 引用通常会指向主分支的最新一次提交。
伪代码:
1 | references = map<string, string> // <可读的名称,对象的 id > |
所以至此,Git仓库的定义也就明确了由对象与引用两部分组成。
Git 命令
暂存区:git让用户在创建快照是能够自由选择需要上传哪些更改,而暂存区就实现了这个功能。主要是通过add命令去将想要的改动上传到暂存区然后再使用commit将暂存区的内容进行提交实现的。这也是为什么没有git snapshot命令的原因。
- 基础命令
git init: 初始化 git 仓库,其数据会存放在一个名为 .git 的目录下。git help <command>: 获取 git 命令的帮助信息。(EX:git help init)git status: 显示当前的仓库状态git add <filename>: 添加文件到暂存区git commit: 创建一个新的提交,使用-m编写提交信息(提交信息是相当重要的)git log: 显示历史日志。-x选项可用于查看最新的x次提交(x 为具体的数字)git cat-file -p <HASH值>:输出对象的具体内容(内部命令)git log --all --graph --decorate: 可视化历史记录(有向无环图)git checkout <commit的hash值/分支名>: 移动 HEAD 到指定的 commit 上/切换工作目录到指定的分支上。(注意,使用git checkout会销毁所有的未提交的改动内容)git diff <文件名>: 显示 HEAD 与暂存区文件的差异(HEAD 是指向最后一个 commit 的,而当前工作目录是独立的)git diff <指定的commit的hash值> <文件名>: 显示某个文件在当前工作目录与指定版本之间的差异。可以通过传入两个版本进行两个版本之间的比较,比如:git diff 42fba7a29 HEAD <文件名>。git checkout <文件名>:将指定的文件内容设置为 HEAD 所指向的快照的状态。
- 分支与合并
git branch: 显示分支,-vv参数会打印更详细的信息git branch <name>: 创建分支git checkout -b <name>: 创建分支并切换到该分支。相当于git branch <name>; git checkout <name>git merge <分支名>: 合并到当前分支,--abort参数可以退回合并前的状态。git mergetool: 使用工具来处理合并冲突git rebase: 将一系列补丁变基(rebase)为新的基线
- 远端操作
使用Git与他人协作的方式是其他人也可以拥有整个Git仓库的副本。其他人的本地仓库可以知道其他克隆副本的存在。
git remote: 列出所有当前仓库所知道的远程仓库git remote add <远程仓库名称> <远程仓库url>: 添加一个远程仓库,如果只使用一个远程仓库,远程仓库名称使用origingit push <远程仓库名称> <本地分支名称>:<远程分支名称>: 在远程仓库创建一个新分支然后推送本地分支上的内容或更新上面的一个分支git clone <远程仓库url> <本地存储路径>: 用于获取远程仓库的副本,并使用该副本来初始化本地仓库git branch --set-upstream-to=<远程仓库名称>/<远程仓库分支>: 创建本地分支(这里是当前所在分支)和远端分支的关联关系(比如原来需要git push origin master:master,执行git branch --set-upstream-to=origin/master后就只需要git push)(HEAD 在 master 处)git fetch <远程仓库url>: 用于检索在远程仓库上的更改并在本地上获取这些更改(只有一个远程仓库的话就不需要输入 url 了)git pull <远程仓库url>: 相当于git fetch; git merge。git merge在这里将本地分支更新到与远程分支指向相同位置。
- 其他
git config:修改Git的配置文件git clone --shallow: 浅克隆,不包括完整的版本历史信息,只有最新的快照,用于克隆大仓库git add -p:交互式暂存,用于选择文件的哪些内容需要 commit 哪些不用(比如一些用于调试的代码)(更加灵活的一种方式)git blame: 查看最后修改某行的人git stash: 将当前工作目录的修改储藏起来,使其暂时脱离当前分支的影响。一些更具体的操作如下:git stash push:保存当前工作目录中的修改到栈中。git stash list:查看保存在栈中的所有储藏。git stash apply:将最新的储藏内容应用到当前工作目录,但并不删除这个储藏。git stash pop:将最新的储藏内容应用到当前工作目录,并将这个储藏从栈中删除。git stash drop:丢弃最新的储藏内容,从栈中删除。git bisect: 通过二分查找搜索历史记录.gitignore文件: 指定Git不需要追踪的文件
第7讲 - 调试及性能分析
调试
打印调试法与日志
调试代码的第一种方法往往是你发现一些代码的行为和你想象的不一样,所以通过添加打印语句来进行调试。这种方法简单且反馈很快。
但是这种方法也有问题,你可能会得到大量的输出而无法准确定位到真正有用的信息。
另外一个方法是使用日志,与打印调试发相比,它的优势在于:
- 在复杂的软件系统中可以在某些事件发生时把它们记录下来
- 日志的核心优势是支持严重等级(例如 INFO, DEBUG, WARN, ERROR等)并且可以根据这些级别过滤日志,这有助于锁定我们需要的信息(可读性也更高)
- 对于新发现的问题,很可能您的日志中已经包含了可以帮助您定位问题的足够的信息。
有很多技巧可以使日志的可读性变得更好,比如使用颜色高亮,但我们要怎么在终端里实现呢?
在这里,我们执行echo -e "\e[38;2;255;0;0mThis is red\e[0m"会打印红色的字符串This is red。这里的255;0;0是告诉终端我们想要的RGB值。
第三方日志系统
当在构建大型软件系统时,可能会有一些依赖项,比如 Web 服务器或数据库。这些依赖项会在自己的日志中记录他们的错误或者异常,这时阅读它们的日志就非常有必要了,因为仅靠客户端侧的错误信息可能并不足以定位问题。
在大多数 UNIX 系统中,程序的日志通常存放在/var/log下。可以通过查看system.log(或者syslog)去查看系统日志。
一般来说,每个软件都有自己的日志,现在更流行的做法是将所有日志都放在系统日志中,这些日志不是以普通的文本格式存储,而是以某种特殊格式压缩过的。journalctl命令将帮助我们访问并输出日志的内容。
我们可以使用logger命令来记录日志,比如:logger "Hello logs",然后用journalctl --since "1m ago" | grep Hello来查看刚刚写入的日志。
调试器
调试器是一种工具,它会运行你的代码,可以操控你的程序,比如:设置断点。
这里介绍的是Python的调试器是pdb以及对gdb的简单提及,建议去看视频演示。
专门工具
即使您需要调试的程序是一个二进制的黑盒程序,仍然有一些工具可以帮助到您。在 Unix 系统中,有用户级代码和内核级代码的概念。当你尝试执行一些操作,例如读取文件或读取网络连接时,你得执行系统调用。你可以获取一个程序并查看其操作,询问该软件执行了哪些操作。有一些命令可以帮助您追踪您的程序执行的系统调用,这里我们使用strace。
下面的例子展现来如何使用strace来显示ls执行时,对系统调用进行追踪的结果。
1 | sudo strace ls -l > /dev/null |
结果会输出所有执行ls所需要的所有的系统调用。
1 | sudo strace ls -e lstat -l > /dev/null |
lstat用于查看文件的属性
根据正在执行的任务的不同,将有不同类型的调试器可用。比如,对于 Web 开发, Chrome 和 Firefox 都有非常好用的调试 Web 的工具,功能也很强大。
静态分析
有些问题是您不需要执行代码就能发现的,例如,某个循环变量覆盖了某个已经存在的变量名,或是有个变量在被使用之前并没有被定义。这种情况下静态分析工具就可以帮我们找到问题。
静态分析工具会将程序的源码作为输入,对其进行处理,并指出代码的哪些部分可能是错误的。
这边介绍的是python的pyflakes与mypy。
对于其他语言的开发者来说,静态分析工具可以参考这里writegood:英语静态分析工具,可用于检查拼写错误或进行很多不同类型的风格分析。
性能分析
性能分析可以帮助你优化代码,比如CPU、内存、网络方面的性能。
计时
最简单的一种方法就是使用printf语句,在需要调试的代码块前后分别加上printf语句打印时间,然后使用变量计算时间差。不过,执行时间也可能会误导您,因为您的电脑可能也在同时运行其他进程,也可能在此期间发生了等待。对于工具来说,需要区分真实时间、用户时间和系统时间。真实时间是指从程序运行开始到结束的总时间,然后用户时间是指CPU执行用户级别的代码所用的时间,系统时间则是执行内核级别的指令所花费的时间。通常来说,用户时间+系统时间代表了您的进程所消耗的实际 CPU 。
1 | time curl https://missing.csail.mit.edu &> /dev/null |
该命令用于查看curl命令的三个指标,如图:
可以看出来,大部分时间都花在了等待网络响应上。
计时有时并不是非常好用,如果过多使用也会导致代码变得混乱难以维护。因此我们会有更好的工具,通常称之为”分析器”。
性能分析工具(profilers)
一般提及分析器指的是 CPU 分析器。CPU 性能分析工具有两种:跟踪分析器及采样分析器。
跟踪分析器会在代码中插入一些东西,会与你的代码一起执行,然后在程序进入函数调用时记录相关信息,完成后就会告诉各个函数的执行时间。跟踪分析器的问题在于会增加很多开销,影响程序的性能。
而采样分析器会执行你的程序,然后每隔一段时间停止程序,然后告诉你执行的进度,哪些函数正在执行。
课堂以对grep的一个简单实现的python代码为案例。
同样的,我们也有内存分析器,用于检查内存分配,消耗多少内存,查看总内存使用量和增量。
perf命令会报告与您的程序相关的系统事件,常见命令如下:
perf list:列出可以被pref追踪的事件;perf stat 命令 ARG1 ARG2:收集与某个进程或指令相关的事件,比如:sudo perf stat stress -c 1perf record 命令 ARG1 ARG2:记录命令执行的采样信息并将统计数据储存在perf.data中,比如:sudo perf record stress -c 1perf report:格式化并打印perf.data中的数据。
比起一大堆的数据,使用可视化工具会更容易理解,比如火焰图, Y 轴显示堆栈的深度, X 轴显示其耗时的比例。
htop是一个交互式的命令行工具,用于显示当前运行进程的多种统计信息。du是一个磁盘内存分析工具,du -h 指定目录可以查看指定目录下的所有文件的大小。ncdu是一个交互性更好的du,它可以让您在不同目录下导航、删除文件和文件夹。lsof可以列出被进程打开的文件信息,当我们需要查看某个文件是被哪个进程打开的时候,这个命令非常有用。(sudo lsof)
第8讲 - 元编程
本节课主要讲在软件开发中涉及的一些工作流程,起名元编程是我们能够想到的最能概括它们的词。
构建系统
概念:将构建目标需要运行的命令按序写到一个工具中,让这个工具自动地为你执行这些命令。make是最常用的构建系统之一,它不适用与构建非常复杂的项目,但对于简单或者中等复杂度的东西都可以很好地工作。make将在当前目录中查找一个名为Makefile的文件,我们会在这里定义我们的目标、依赖项和规则。
示例:
1 | paper.pdf: paper.tex plot-data.png |
paper.tex plot-data.png是构建paper.pdf的依赖项。pdflates paper.tex将paper.tex转换为paper.pdf。plot-data.png会被嵌入pdf文件中。要注意,两个依赖项文件必须存在且任意一个发生变化都会重新生成pdf。(如果依赖项没有发生变化而执行make,make不会重新构建paper.pdf)。
第二部分演示的是依赖传递。%代表任意字符。第二部分的意思是当有一个目标%.dat与前面的%匹配(比如有一个foo.dat且目标文件名为plot-foo.png,就会使用foo.dat这个文件)并且存在plot.py时,就执行./plot.py -i $*.dat -o $@。$*的意思是不管前面的%是什么都可以成功匹配,$@则表示目标文件的名称,也就是plot-%.png。
依赖关系
在开发工作中,项目会有多种不同的依赖关系。比如文件,程序,库/系统库等等。现在,大多数的依赖可以通过某些软件仓库来获取,这些仓库会在一个地方托管大量的依赖,我们则可以通过一套非常简单的机制来安装依赖。
当我们使用仓库的时候,我们会注意到很多软件都有版本号,通常看上去像8.1.3或 64.1.20192004。为什么我们需要用到版本号呢?主要是它能够让我们知道软件是否会出现 bug ,比如我的库发布了一个新版本,在这个版本里面我重命名了某个函数,如果有人在我的库升级版本后,仍希望基于它构建新的软件,那么很可能构建会失败,因为他希望调用的函数已经不复存在了。而版本可以解决这个问题,我们可以指定当前项目需要基于某个版本,甚至是某个范围内的版本。
对于版本号的格式与命名,我们通常使用这种格式:主要版本号.次要版本号.补丁版本号,其规则如下:
- 对软件进行了完全向前兼容的更改(例如未增删改任何东西),增加补丁版本号。(安全修复)
- 添加了库中的某些内容,增加次要版本号并将补丁号设置为 0
- 进行了向前不兼容的更改(删改函数名),增加主要版本号并将次要版本号与补丁号设置为 0
因此,当我们依赖于某个库的特定版本时,也可以选择其他版本进行更换,遵循:主版本必须相同,次要版本可以相同,补丁号可以不用管即可。
使用依赖管理系统的时候,我们可能会遇到锁文件,它本质是个列表,列出了当前每个依赖所对应的具体版本号。锁文件的存在是为了确保你不会意外更新某些不应该更新的东西从而导致一些意外的 bug 产生。
持续集成系统
本质上就是一个云构建系统,它可以是将你的库自动发布到 PyPI 当你每次提交到特定分支时,或者是当有人提交 pr 时运行测试套件,或者是提交代码时对代码风格进行检查。市场上有各式各样 CI 工具,涵盖了许多方面,像 Github actions 就是一个广泛的 CI 平台。
测试套件
测试套件是对程序中所有测试的简称,它是一组测试,通常作为一个整体运行,且由不同测试组成:
- 单元测试:一种”微型测试”,用于测试一个单一的功能。
- 集成测试:一种”宏观测试”,针对系统的某一大部分进行,测试程序的不同子系统之间的交互。
- 回归测试:一种实现特定模式的测试,测试过去出现过问题的东西。
- 模拟:也就是打桩,用虚拟的方式替换掉测试中的某些部分(比如网络连接)。


