
excelize 相关记录
Excel 中自定义数字格式代码
四个区段
完整的自定义的格式代码分为四个区段,中间以”;”间隔,每个区段中的码对应不同类型的内容,如下所示:
对正数应用的内容 ; 对负数应用的内容 ; 对零值应用的内容 ; 对文本应用的内容。
但在实际应用中,区段数是可以小于4个的,结构含义如下所示:
- 区段数为 1 :作用于所有类型的格式
- 区段数为 2 :对正数和零值应用的格式 ; 对负数应用的格式
- 区段数为 3 :对正数应用的格式 ; 对负数应用的格式 ; 对零值应用的格式
(PS:在区段为 2 时,如果第二个区段以”@”开头,第二个区段为对文本应用的内容)
常用自定义格式代码符号及其含义
三个数字占位符
#: 显示单元格中原有的数字,但不显示无意义的零值。0: 显示单元格中原有的数字,当数字位数少于代码的位数时,显示无意义的零值。?: 与0作用类似,但用空格代替无意义的零值
如图所示: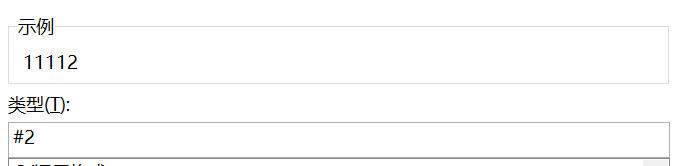
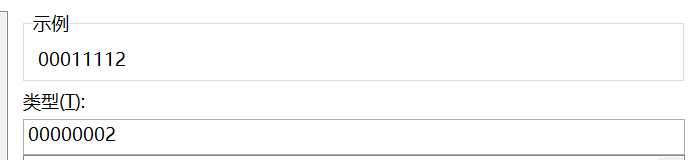
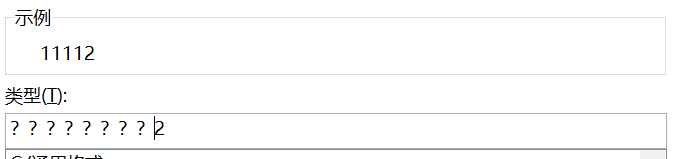
数字定义相关
.: 小数点%: 百分数,: 千位分隔符E: 科学记数符号
颜色设置
[颜色]: 中括号中的内容为对应的颜色,可以是中文也可以是英文,如[RED]与[红色]都可以。
条件设置
[条件]: 中括号中的内容为具体条件,由>、<、=、>=、<=、<>跟具体数值所构成。若单元格的数字若不在限定的条件之内,则无法正常显示。
格式转换
[DBNuml]: 显示中文简体数字,如123显示为一百二十三。[DBNum2]: 显示中文繁体数字,如123显示为壹佰贰拾参。[DBNum3]: 显示全角的阿拉伯数字与中文简体单位的结合,如123显示为1百2十3。
地区设置
[$-语言地区标识/标签]: 为指定单元格应用对应地区的时间、日期定义,如[$-404]与[$-zh-TW]都是指代台湾地区。
(PS: WPS 不支持这种自定义格式代码,EXCEL 2013 版仅支持语言地区标识。)
其他
"": 可显示双引号之间的文本。!: 强制显示!或\之后的一个字符(有点转义字符的意思)。\: 同上。*: 重复下一个字符。_: 留出一个字符宽度的空格。@: 文本占位符,显示单元格中原有的文本。
与日期时间格式相关的代码符号
aaa: 使用中文简写显示星期几,如:一。aaaa: 使用中文全称显示星期几,如:星期一。d: 使用没有前导零的数字来显示日期,如:1。dd: 使用有前导零的数字来显示日期,如:01。ddd: 使用英文缩写显示星期几,如:Sun。dddd: 使用英文全称显示星期几,如:Sunday。m: 使用没有前导零的数字来显示月份或分钟。mm: 使用有前导零的数字来显示月份或分钟mmm: 使用英文缩写显示月份mmmm: 使用英文全拼显示月份mmmmm: 使用英文首字母显示月份y: 使用两位数字显示公历年份,如:01。yy: 同上yyyy: 使用四位数字显示公历年份,如:1901。h: 使用没有前导零的数字来显示小时,如:1。hh: 使用有前导零的数字来显示小时,如:01。S: 使用没有前导零的数字来显示秒,如:1。SS: 使用有前导零的数字来显示秒,如:01。[h]、[m]、[s]: 显示超出进制的小时数、分数、秒数。AM/PM: 使用英文上下午显示 12 进制的时间。AP: 同上。上午/下午: 使用中文上下午显示 12 进制的时间。
Excelize中设置数字格式表达式以及相关源码分析
示例代码
在 Excelize 中,我们可以通过使用 Style 来为指定单元格设置数字格式,下面是示例代码:
1 | package main |
结果如图所示: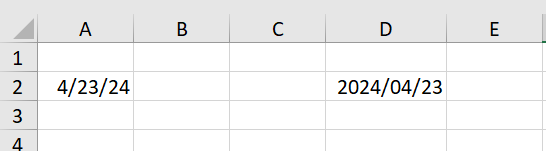
源码分析
这里我们只专注于与 numfmt 相关的源码。
NewStyle
函数部分内容如下:
1 | func (f *File) NewStyle(style *Style) (int, error) { |
分析:
parseFormatStyleSet函数用于解析单元格的格式设置和条件格式,里面对 style.CustomNumFmt 进行了条件判断:如果 style.CustomNumFmt 不为 nil 且其指向的字符串长度为0,函数返回 err 为 ErrCustomNumFmt 错误。stylesReader方法在对xl/styles.xml进行解析后将具体内容反序列化到 f.Styles 之中。
f.Styles 为 *xlsxStyleSheet , 结构体的部分相关定义如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22// NumFmts: 一个指向 xlsxNumFmts 结构体的指针,表示自定义数字格式的集合。
type xlsxStyleSheet struct {
// ...
NumFmts *xlsxNumFmts `xml:"numFmts"`
// ...
}
// Count:一个整数类型的字段,指示了 NumFmt 切片中元素的数量。
// NumFmt:一个指向 xlsxNumFmt 结构体切片的指针,表示自定义数字格式的集合,切片中的每一个元素都代表一个自定义数字格式。
type xlsxNumFmts struct {
Count int `xml:"count,attr"`
NumFmt []*xlsxNumFmt `xml:"numFmt"`
}
// NumFmtID:一个整数类型的字段,表示自定义数字格式的唯一的ID,用于在XML中引用该格式。
// FormatCode:一个字符串类型的字段,表示自定义数字格式表达式的内容。
// FormatCode16:。。。其实不是很懂这是啥。
type xlsxNumFmt struct {
NumFmtID int `xml:"numFmtId,attr"`
FormatCode string `xml:"formatCode,attr"`
FormatCode16 string `xml:"http://schemas.microsoft.com/office/spreadsheetml/2015/02/main formatCode16,attr,omitempty"`
}newNumFmt函数用于在Excel的样式表(xlsxStyleSheet)中创建一个新的自定义数字格式(xlsxNumFmt)并返回其ID。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108func newNumFmt(styleSheet *xlsxStyleSheet, style *Style) int {
// 初始化默认的自定义数字格式代码 dp 为 "0",并且设置默认的自定义数字格式ID numFmtID 为 164(货币格式的开头)。
dp, numFmtID := "0", 164
// 如果 style.DecimalPlaces (小数点位数)不为 nil 并且大于 0,则在 dp 中添加小数点和相应数量的 0。
if style.DecimalPlaces != nil && *style.DecimalPlaces > 0 {
dp += "."
for i := 0; i < *style.DecimalPlaces; i++ {
dp += "0"
}
}
// 处理自定义数字格式
// 如果 style.CustomNumFmt 不为 nil,则尝试获取自定义数字格式的ID。如果自定义数字格式已经存在于样式表中,返回其ID;
// 否则,调用 setCustomNumFmt 函数来设置新的自定义数字格式,并返回其ID。
if style.CustomNumFmt != nil {
if customNumFmtID := getCustomNumFmtID(styleSheet, style); customNumFmtID != -1 {
return customNumFmtID
}
return setCustomNumFmt(styleSheet, style)
}
// 处理使用内置的数字格式
// 检查是否已经有一个内置的数字格式与 style.NumFmt 匹配,有就直接返回
if _, ok := builtInNumFmt[style.NumFmt]; !ok {
// 不匹配尝试获取货币格式
fc, currency := currencyNumFmt[style.NumFmt]
if !currency { // 不是货币格式就去看是不是地区时间数字格式
return setLangNumFmt(style) // 是直接返回 style.NumFmt,不是返回 0
}
// 是货币格式进行以下处理
// 如果 style.DecimalPlaces 不为 nil,则替换内置货币格式中的 "0.00" 为之前计算的 dp。
if style.DecimalPlaces != nil {
fc = strings.ReplaceAll(fc, "0.00", dp)
}
// 如果 style.NegRed 为 true,则在格式代码后面添加红色负数的格式。
if style.NegRed {
fc = fc + ";[Red]" + fc
}
// 如果 styleSheet.NumFmts 为 nil,则初始化一个新的 xlsxNumFmts 结构体。
// 否则,获取最后一个 styleSheet.NumFmts.NumFmt 的 ID,并为新格式分配一个比最后一个 ID 大的 ID。
if styleSheet.NumFmts == nil {
styleSheet.NumFmts = &xlsxNumFmts{NumFmt: []*xlsxNumFmt{}}
} else {
numFmtID = styleSheet.NumFmts.NumFmt[len(styleSheet.NumFmts.NumFmt)-1].NumFmtID + 1
}
// 创建一个新的 xlsxNumFmts 结构体并追加到 styleSheet.NumFmts.NumFmt 中
styleSheet.NumFmts.NumFmt = append(styleSheet.NumFmts.NumFmt, &xlsxNumFmt{
FormatCode: fc, NumFmtID: numFmtID,
})
styleSheet.NumFmts.Count++
return numFmtID
}
return style.NumFmt
}
func getCustomNumFmtID(styleSheet *xlsxStyleSheet, style *Style) (customNumFmtID int) {
customNumFmtID = -1
if styleSheet.NumFmts == nil {
return
}
for _, numFmt := range styleSheet.NumFmts.NumFmt {
// 如果 styleSheet.NumFmts.NumFmt 中已经有了相同的数字格式,返回这个的 ID
if style.CustomNumFmt != nil && numFmt.FormatCode == *style.CustomNumFmt {
customNumFmtID = numFmt.NumFmtID
return
}
}
return
}
func setCustomNumFmt(styleSheet *xlsxStyleSheet, style *Style) int {
nf := xlsxNumFmt{NumFmtID: 163, FormatCode: *style.CustomNumFmt}
if styleSheet.NumFmts == nil {
styleSheet.NumFmts = &xlsxNumFmts{}
}
// 找到 styleSheet.NumFmts.NumFmt中所有 ID 的最大值 , 让 nf 的 ID 成为最大值
for _, numFmt := range styleSheet.NumFmts.NumFmt {
if numFmt != nil && nf.NumFmtID < numFmt.NumFmtID {
nf.NumFmtID = numFmt.NumFmtID
}
}
nf.NumFmtID++
// 追加元素
styleSheet.NumFmts.NumFmt = append(styleSheet.NumFmts.NumFmt, &nf)
styleSheet.NumFmts.Count = len(styleSheet.NumFmts.NumFmt)
return nf.NumFmtID
}
// 查看是不是地区时间数字格式
func setLangNumFmt(style *Style) int {
if isLangNumFmt(style.NumFmt) {
return style.NumFmt
}
return 0
}
func isLangNumFmt(ID int) bool {
return (27 <= ID && ID <= 36) || (50 <= ID && ID <= 62) || (67 <= ID && ID <= 81)
}setCellXfs设置描述单元格的所有格式到 Xf 结构体中,然后style.CellXfs.Xf = append(style.CellXfs.Xf, xf)进行内容追加,最后return style.CellXfs.Count - 1返回 style 的 ID 。
其他函数关系就不太大了,主要还是 NewStyle 。
excelize 中 numfmt 相关的分析
前置知识 - nfp 的介绍
nfp就是 numfmt parser ,这个包被大量用于 numfmt 之中用于数字解析,这边就简单介绍一下nfp吧。
主要的方法
很显然,最主要的方法肯定就是负责解析的方法,就是下面这个:
1 | func (ps *Parser) Parse(numFmt string) []Section { |
而里面的getTokens方法就是这个解析方法的逻辑主体。
具体原理分析
nfp的解析,就是根据传入的numFmt数字格式代码将其按”;”拆分为 4 个Section(也就是前文说的四个区段)分别进行解析。Section是由Type和Items两部分组成,Type就对应不同区段的类型,Items就是存储解析numFmt参数得到的结果集。Section结构体定义如下所示:
1 | type Section struct { |
TValue对应的是Token的值,TType就是这个Token的类型,Part则是对Token的子部分的一个映射,由Token和Value构成。Part结构体定义如下:
1 | type Part struct { |
解析结果示例
numfmt 对应传入的参数,result 对应最终解析出来的结果。
- 示例一:
1
2
3
4
5
6{
numfmt: "0%",
result: "[{Positive [{0 ZeroPlaceHolder []} {% Percent []}]}]",
}
解析结果中, `Positive`就是 Type ,`[{0 ZeroPlaceHolder []} {% Percent []}]`就是 Items . `{0 ZeroPlaceHolder []}`与`{% Percent []}`就是解析出来的两个 Token .用第一个 Token 进行分析,其中`0`为 TValue ,`ZeroPlaceHolder`为 TType ,`[]`为 Parts,不过这里的 Parts 为空. - 示例二: 更多 Parts 的示例如下:
1
2
3
4
5
6{
numfmt: `[DBNum1][$-zh-CN]h"时"mm"分";"====="@@@"--"@"----"`,
result: "[{Positive [{[DBNum1] SwitchArgument []} {[$-zh-CN] CurrencyLanguage [{{zh-CN LanguageInfo []} }]} {h DateTimes []} {时 Literal []} {mm DateTimes []} {分 Literal []}]} {Text [{===== Literal []} {@ TextPlaceHolder []} {@ TextPlaceHolder []} {@ TextPlaceHolder []} {-- Literal []} {@ TextPlaceHolder []} {---- Literal []}]}]",
}
具体的结果构成分析参照示例一,这边主要是看一下 Parts 这一部分, 如:`[$-zh-CN]`对应的就是`{[$-zh-CN] CurrencyLanguage [{{zh-CN LanguageInfo []}}]}`,`[{{zh-CN LanguageInfo []} }]`就是 Parts 的存储内容。所以其实 Parts 就是负责存储对数字格式表达式中的条件格式的解析结果。1
2
3[<>50] - {<>50 Condition [{{<> Operator []} } {{50 Operand []} }]}
[$ANG] - {[$ANG] CurrencyLanguage [{{ANG CurrencyString []} }]}
[$RD$-1C0A] - {[$RD$-1C0A] CurrencyLanguage [{{RD$ CurrencyString []} } {{1C0A LanguageInfo []} }]}
函数的部分关系图示
如图: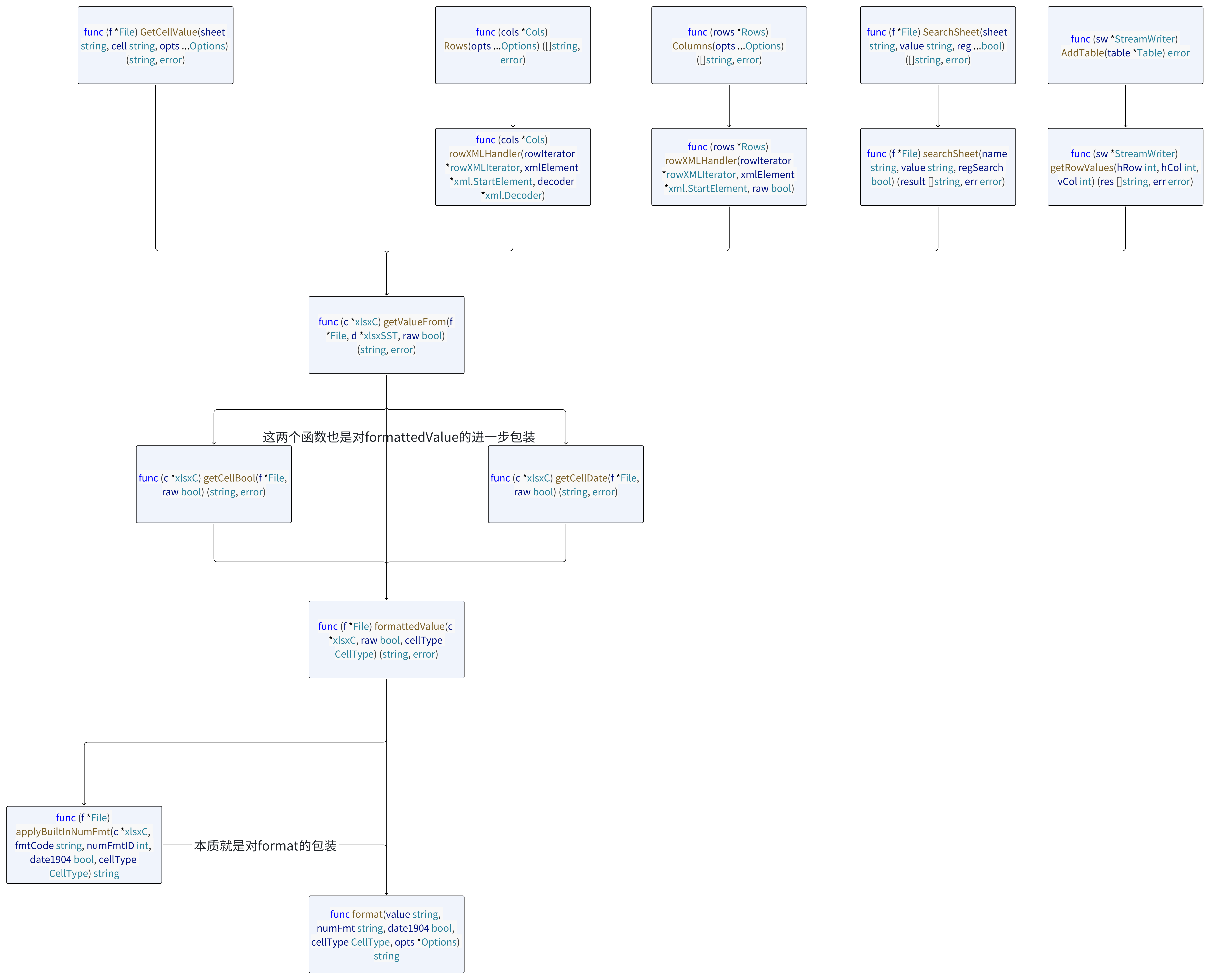
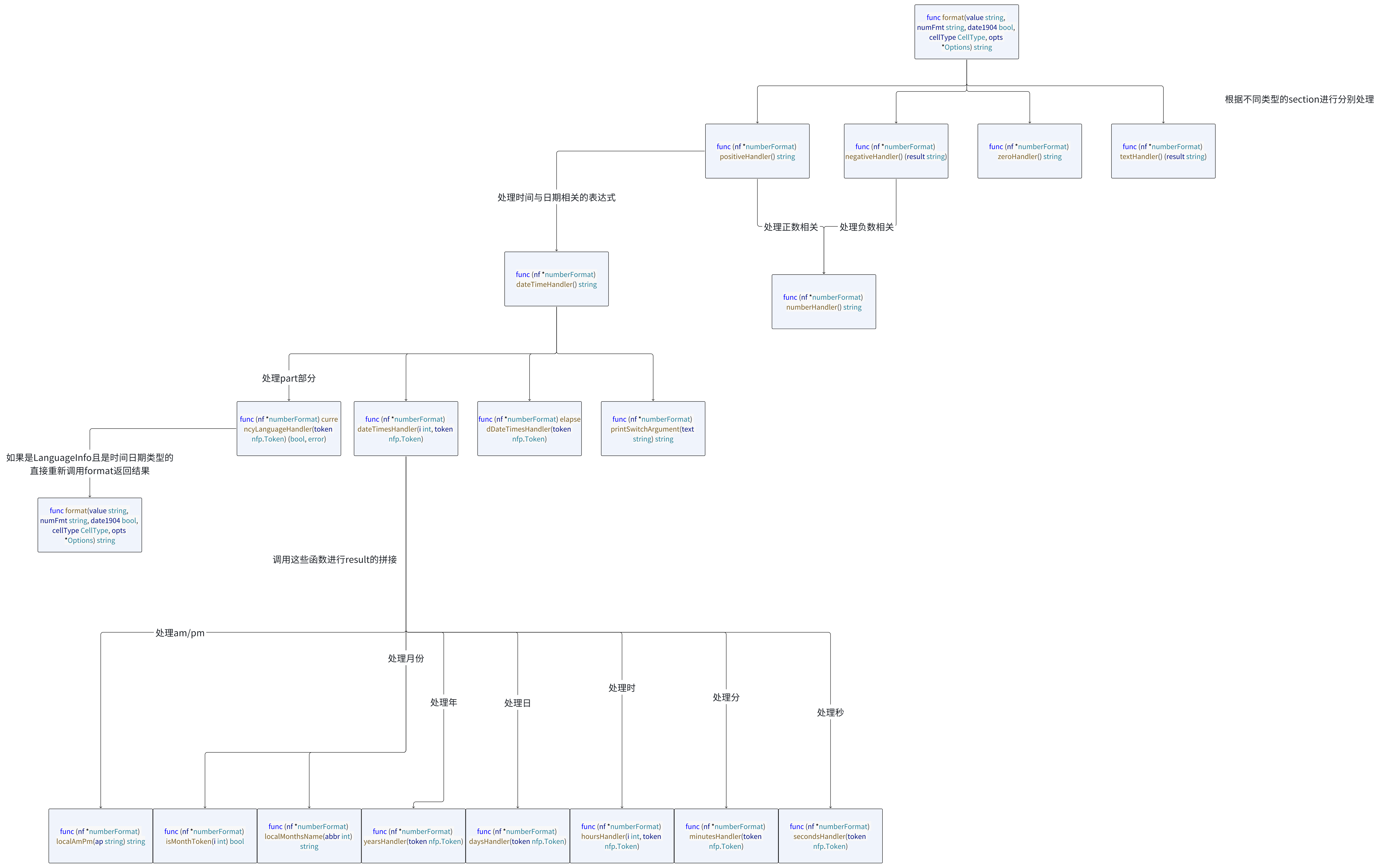
源码分析
这部分主要是集中在 numfmt 的 format 函数的分析,结合 demo 自上而下走一遍。
demo 如下:
1 | func main() { |
GetCellValue
1 | func (f *File) GetCellValue(sheet, cell string, opts ...Options) (string, error) { |
getCellStringFunc主要是从工作流中获取工作表信息,从中提取指定的目标单元格的行列相关信息,执行传入的函数。
getValueFrom
1 | func (c *xlsxC) getValueFrom(f *File, d *xlsxSST, raw bool) (string, error) { |
getValueFrom判断传入的值的类型去选择不同的处理方法,最终返回一个值。
这边走的是 default ,调用 formattedValue 方法。
formattedValue
1 | func (f *File) formattedValue(c *xlsxC, raw bool, cellType CellType) (string, error) { |
formattedValue提供了一个函数用于在格式化后返回一个值。通过查找对应单元格的 numfmtID 去获取对应单元格的数字格式表达式并进行数值的处理。
format
1 | func format(value, numFmt string, date1904 bool, cellType CellType, opts *Options) string { |
format提供了一个函数来返回一个通过数字格式表达式解析的结果,如果给定的数字格式不被支持,这将返回原始的单元格值。
demo 的示例进入positiveHandler。
positiveHandler
1 | func (nf *numberFormat) positiveHandler() string { |
这里传入的 section 的具体内容如下:
1 | { |
所以这边进入dateTimeHandler进行下一步的处理。
dateTimeHandler
1 | func (nf *numberFormat) dateTimeHandler() string { |
因为 token 只由 DateTimes 与 Literal 两个类型构成,所以这边只调用了dateTimesHandler。
dateTimesHandler
1 | func (nf *numberFormat) dateTimesHandler(i int, token nfp.Token) { |
dateTimesHandler按照 am/pm 、月、年、日、时、分、秒将 token 进行区分处理
这边只涉及了月、日、年。
通过将解析的结果按顺序进行拼接,得到的 result 就是最后的结果,返回即可。


